
Technical Brief

ALAMO usage in process optimization
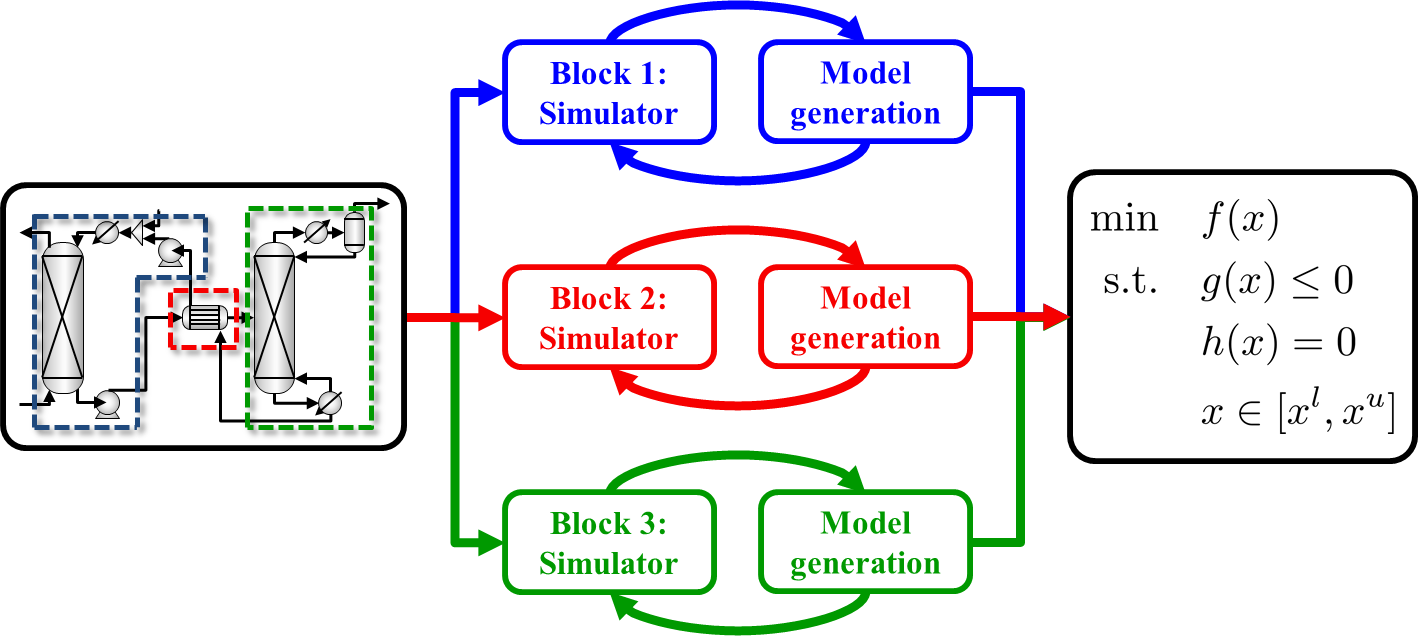
In the case of large complex processes, a simulation can be dissaggregated into process blocks. Each block can be modeled separately, then combine with flexible constraints and connectivity variables to generate a final optimization model.
Notation: Modeling a black-box or process block
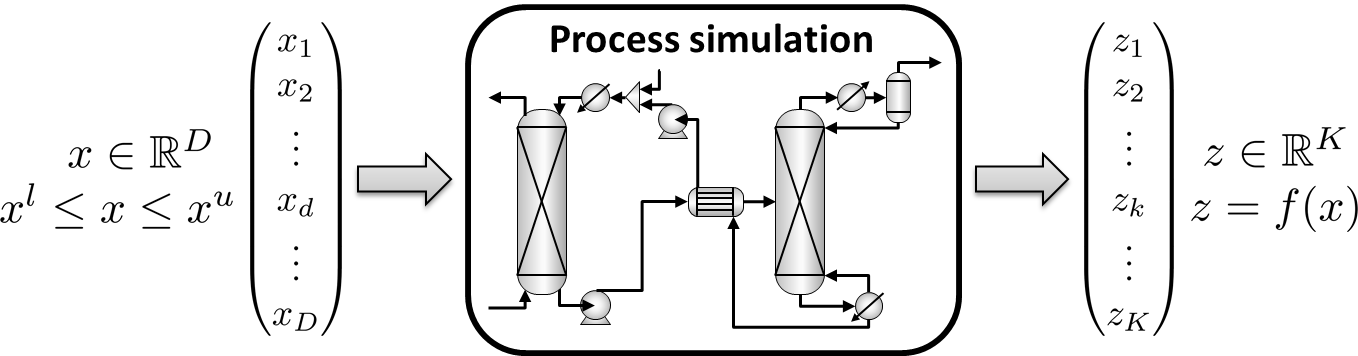
Each process block or black-box will have some set of independent variables,
ALAMO Algorithmic Flowchart
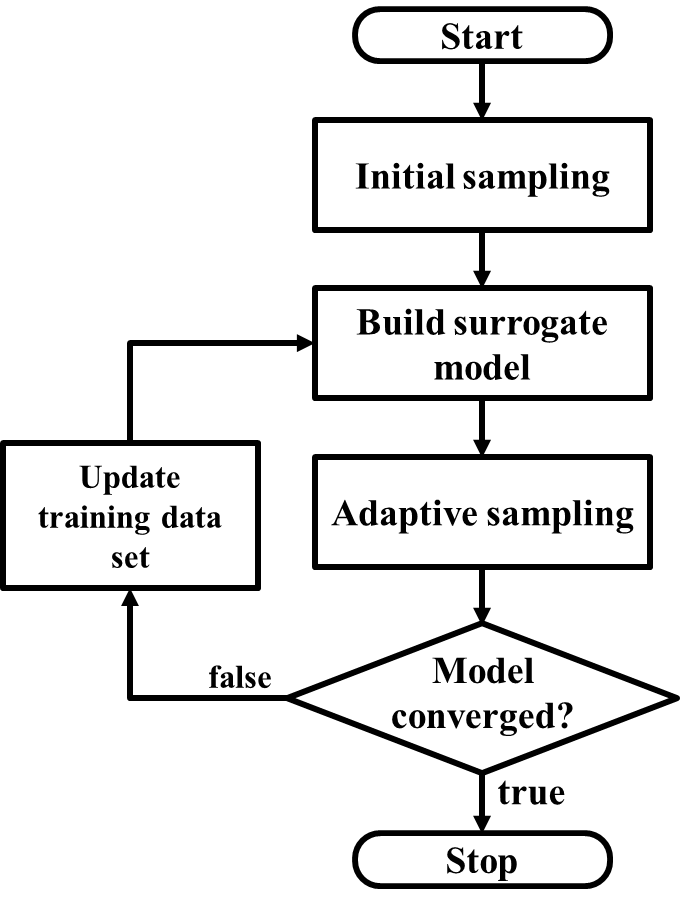
For each output variable,
- Initial design of experiments: Evenly sample the design space to define an initial training set
- Model building: Build a low complexity surrogate model based on the current training set
- Adaptive sampling: By interrogating the system using Error Maximization Sampling (EMS), the training set is updated with new points sampled where the current model breaks down.
- Repeat steps 2 and 3, until no points can be found that violate the model.
In doing this, we aim to generate a model that is
- Accurate
- Simple and compact models for ease the final optimization
- Generated from a minimal data set of simulations or black-box function evaluations
ALAMO Standard Modeling
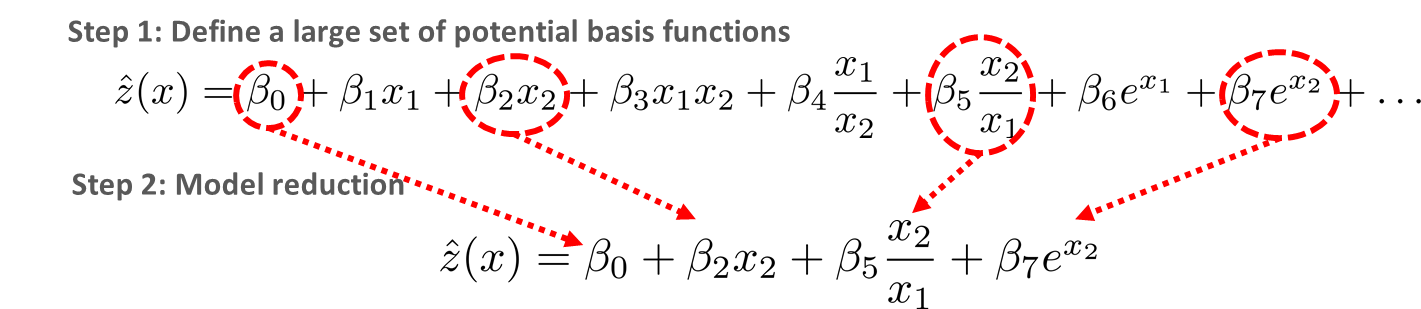
ALAMO does not need to know the functional form of the model in advance. To identify the functional form, ALAMO allows for a large set of potential basis functions that can be found from polynomials, engineering experience, physical phenomena, and statistical fitting functions. Next, by combining optimization techniques and statistical methods, we are able to find a subset of basis functions that accurately model the data without overfitting or using unnecessary terms.
ALAMO Standard Adaptive Sampling
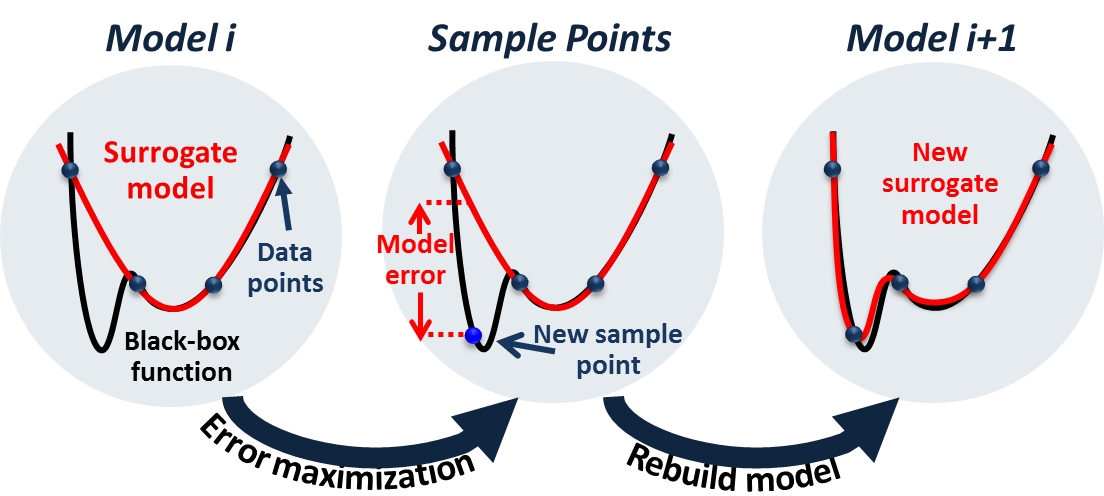
After building the current iterate’s model, ALAMO searches the design space to find where our model breaks down using Error Maximization Sampling (EMS). As the name suggests, EMS solves the black-box problem shown below:

Here, the black-box solver SNOBFIT is used to maximize the relative error. During this process, new function evaluations with high model mismatch are added to the training set. ALAMO will then sample the simulation at these new locations, and rebuild the model.

If, during this step, no points that violate the model can be found, we will consider our model sufficiently accurate.
Related publications
- A. Cozad, N. V. Sahinidis and D. C. Miller, Learning surrogate models for simulation-based optimization, AIChE Journal, 60, 2211-2227, 2014.
- A. Cozad, N. V. Sahinidis and D. C. Miller, A combined first-principles and data-driven approach to model building, Computers and Chemical Engineering, 73, 116-127, 2015.
- Z. T. Wilson and N. V. Sahinidis, The ALAMO approach to machine learning, Computers and Chemical Engineering, 106, 785-795, 2017.
Third party software used
The error maximization adaptive sampling routine in ALAMO uses SNOBFIT, a derivative-free optimization solver. More details about this routine can be found in the SNOBFIT page and the paper: W. Huyer and A. Neumaier, Snobfit -- Stable Noisy Optimization by Branch and Fit, ACM Trans. Math. Software 35 (2008), Article 9. SNOBFIT's quadratic subproblems are solved using MINQ, which is described in: A. Neumaier, MINQ -- General definite and bound constrained indefinite quadratic programming. Web document (1998).